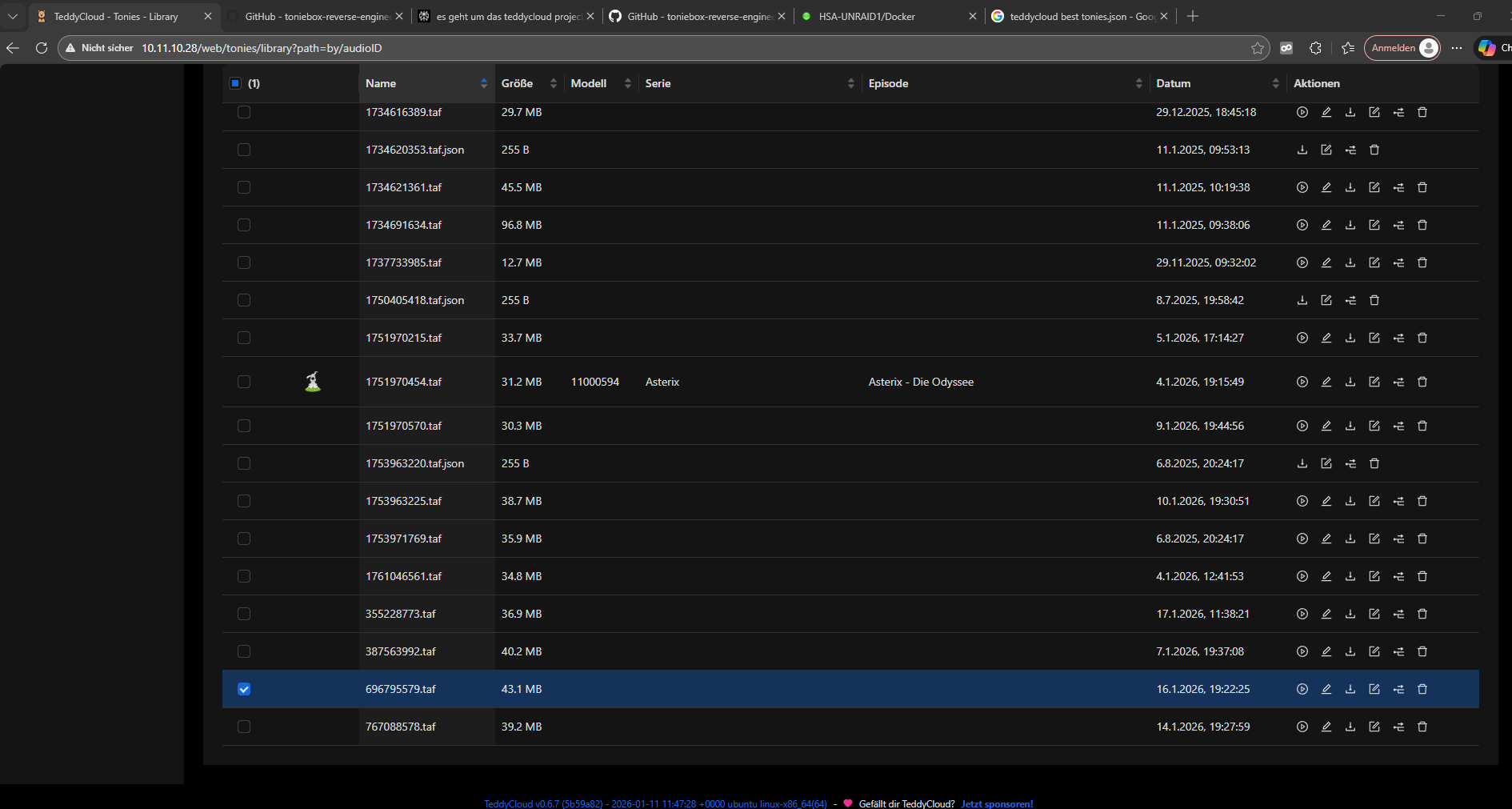
HI,
I have a lot of AudioIDs in the library. Are the AudioIDs not automatically assigned titles such as model series and episode? I imported the latest tonies.json into Docker. What do I need to do?
HI,
I have a lot of AudioIDs in the library. Are the AudioIDs not automatically assigned titles such as model series and episode? I imported the latest tonies.json into Docker. What do I need to do?
Did you reload the json in settings reload tonies json or restarted the teddycloud server afterwards?
That’s necessary.
Besides that still not all tonies have the necessary information in the tonies.json. You can check the missing tonies in teddycloud community section —> contribution —> tonies json