![]() Update Docker: added ARD Audiothek support
Update Docker: added ARD Audiothek support ![]()
I just updated the Docker container with support for ARD Audiothek content. It uses their REST API to retrieve the content (no html scraping). Just copy & paste the link of the content and use it as -s parameter (source).
![]() Usage
Usage ![]()
Command:
docker run --rm -v $(pwd):/data ghcr.io/marco79cgn/audio2tonie transcode -s "[AUDIOTHEK-URL]"
Example URL:
https://www.ardaudiothek.de/episode/3nach9-podcast/hape-birthday-ein-3nach9-spezial-zum-60-geburtstag-von-hape-kerkeling/radio-bremen/13935781/
Output:
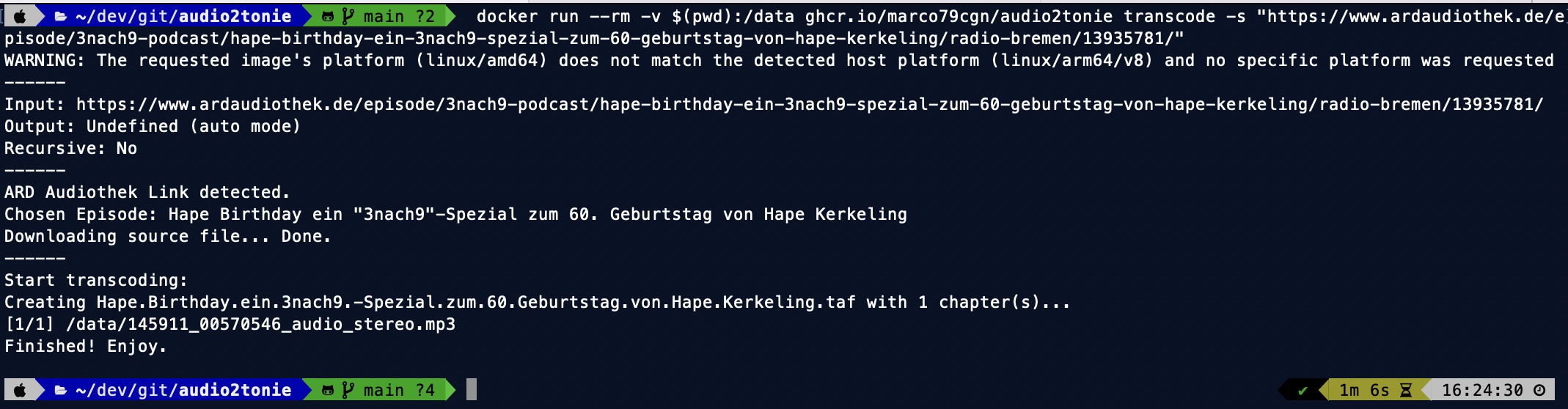
The output filename will be created automatically and produces valid filenames (without unsupported characters), like Hape.Birthday.ein.3nach9.-Spezial.zum.60.Geburtstag.von.Hape.Kerkeling.taf.