![]() Intro
Intro ![]()
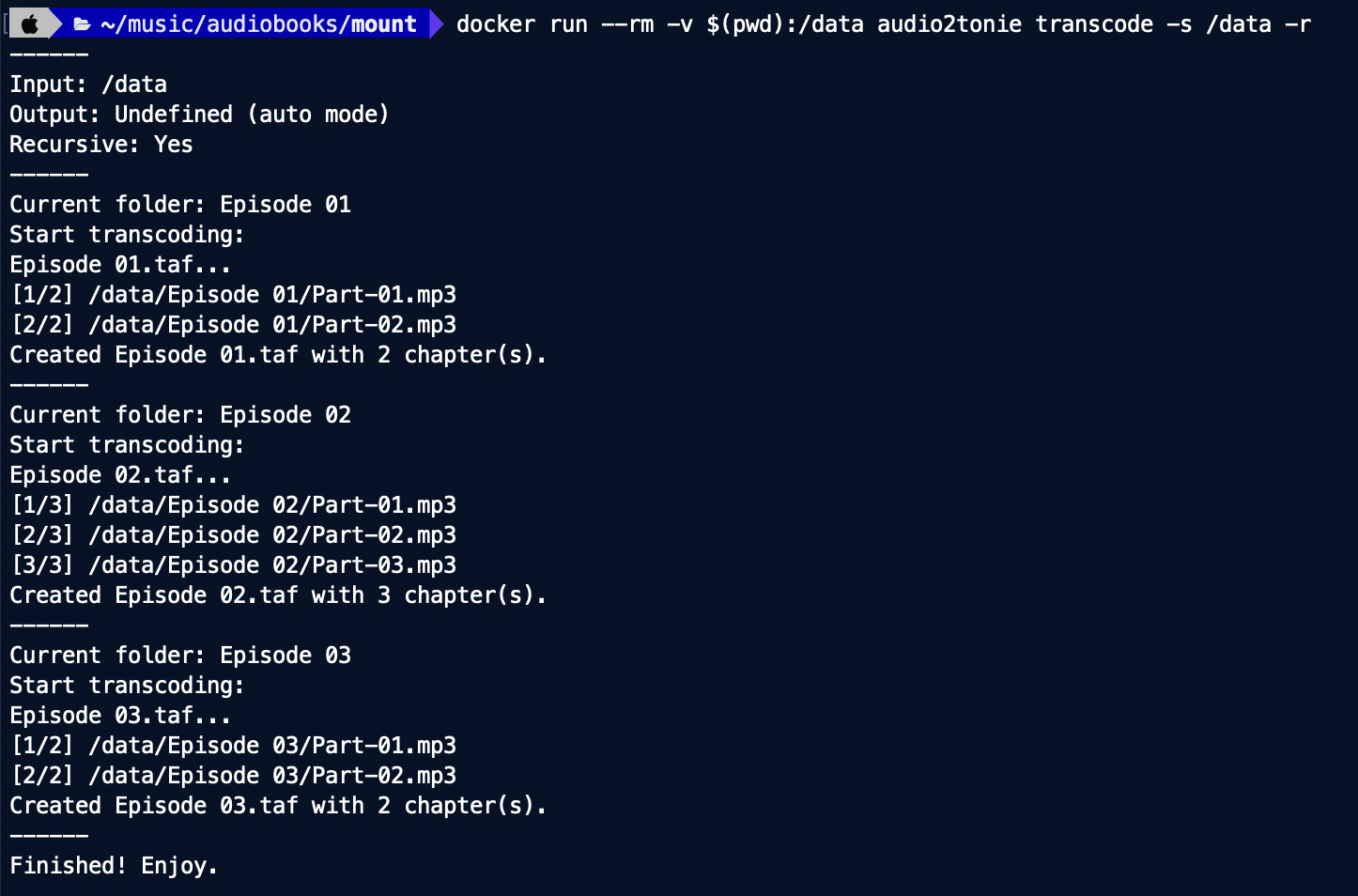
I was looking for a way to encode any audio files into taf as fast as possible on a powerful desktop machine (e.g. MacBook Pro). The Teddycloud has an audio encoder built-in (web interface & cli) but it’s really slow since it’s running on a Raspberry Pi 4 (in my case). Whereas running the teddycloud container on your desktop machine just for taf conversion is a bit overkill and adds unnecessary complexity (docker, handling with volumes, certificate check at every start etc.).
I wanted a solution which is fast, easy to use and easy to automate/script (e.g. for batch conversion of multiple files). As a final result, here’s a time comparison for an audiobook with ~75 minutes playtime.
Transcoding time:
Teddycloud Pi4 (Web/CLI): 7m10s
MacBook M1 Pro (native): 45s
→ roughly 9,5x faster.
![]() Solution
Solution ![]()
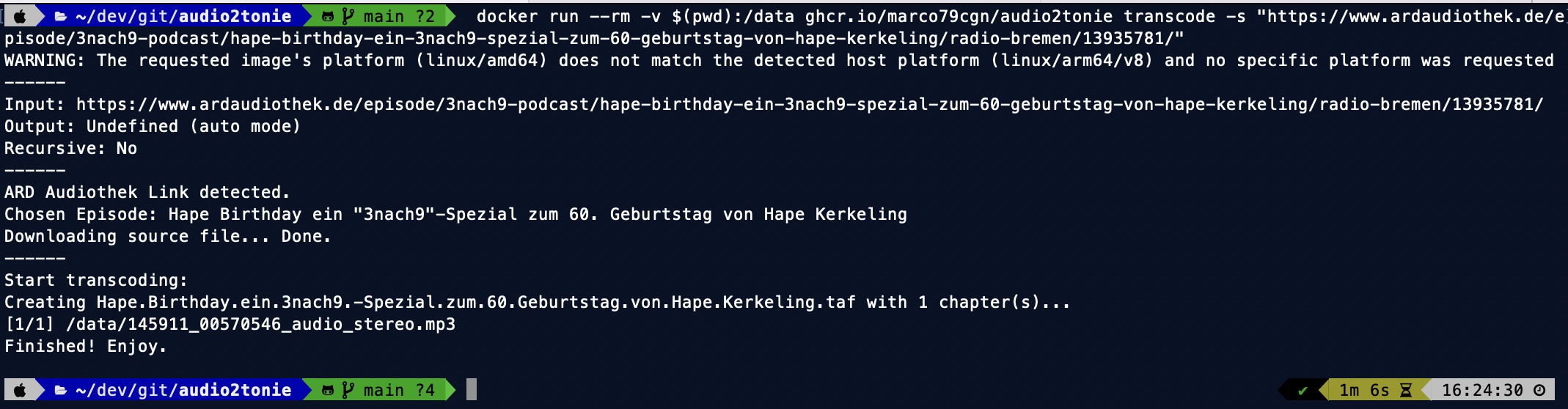
A TAF file is basically an opus sound file but with a special header. That’s why it’s not enough to just encode your audio with tools like ffmpeg. Luckily there’s a python script named Opus2Tonie which automates the process and in this short guide I’ll post installation instructions how to set it up on both macOS and Linux.
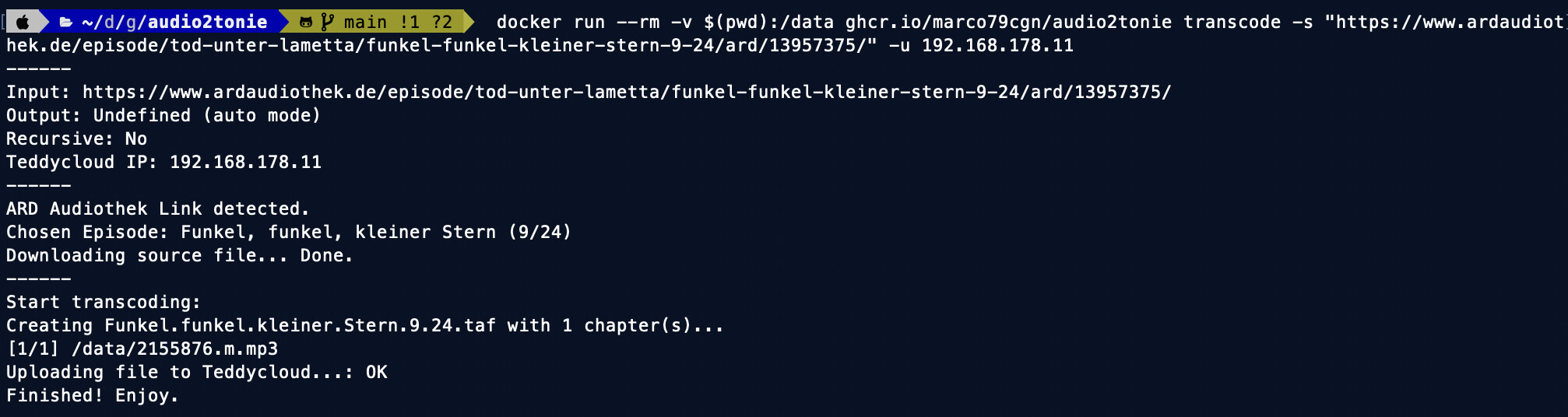
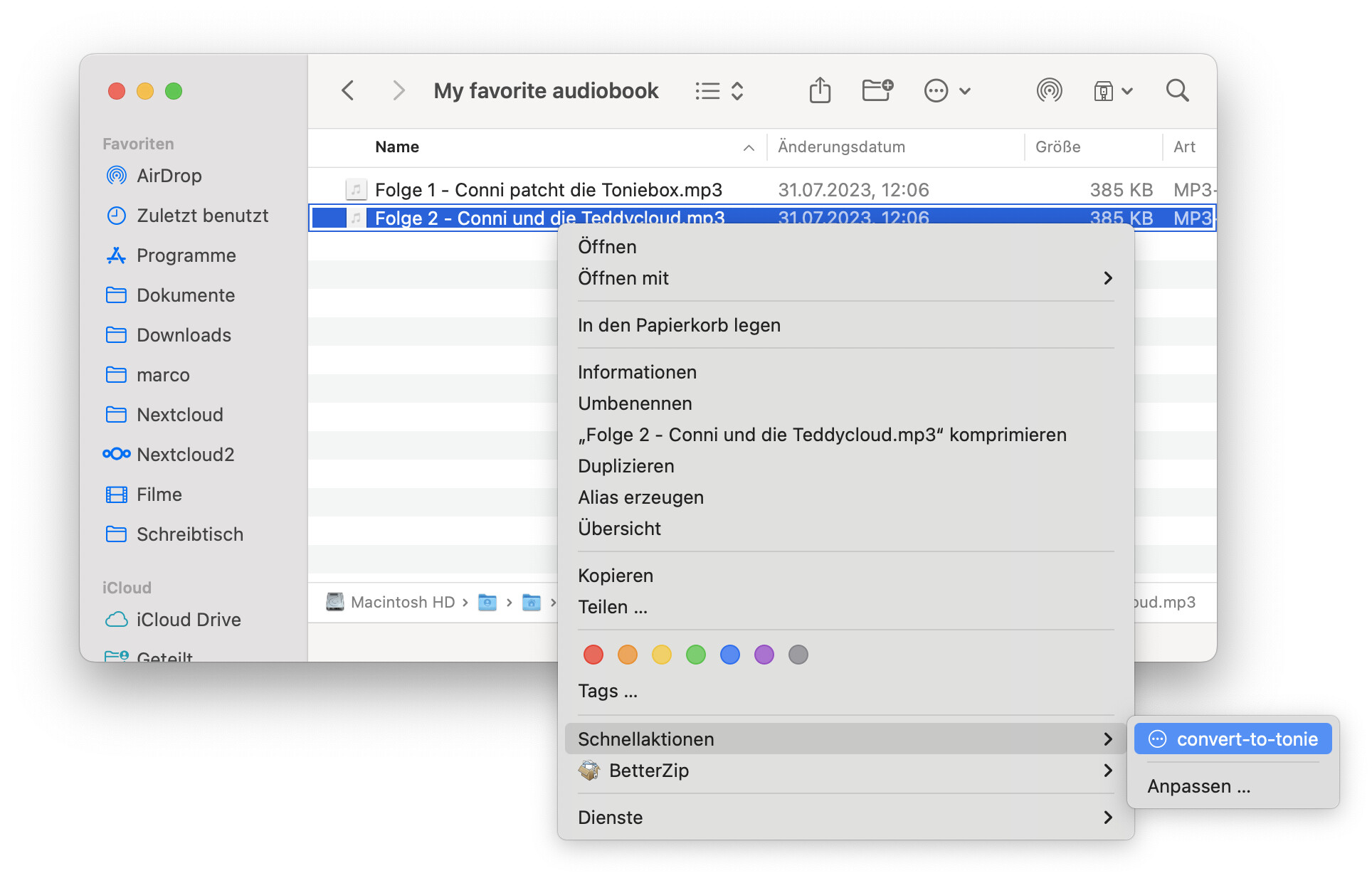
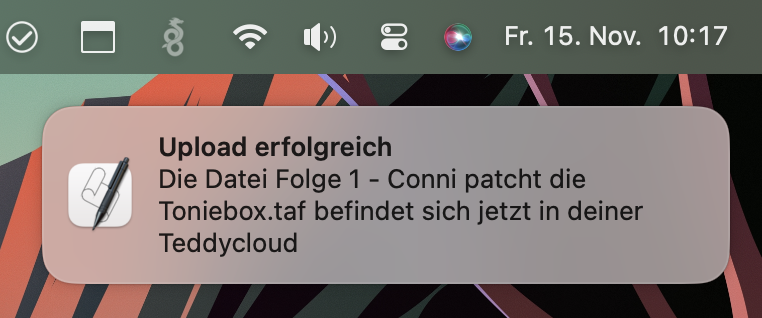
As a second step, instead of using this script only on the command-line, we’ll create a macOS context menu integration which let’s you convert any folder or file with a single mouse click (thx to @ingorichter). Furthermore, the file will even be uploaded to your Teddycloud library and a native system notification is shown at the end.
ㅤ
![]() Installation instructions (macOS/Linux)
Installation instructions (macOS/Linux) ![]()
- install Homebrew (macOS-only)
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
- install ffmpeg
brew install ffmpeg / sudo apt install ffmpeg -y
- install opus-tools
brew install opus-tools / sudo apt install opus-tools
- install python
brew install python@3.13 / sudo apt install python3.13
- setup python3
cd
python3 -m venv .venv
source .venv/bin/activate
- install google protobuf
pip3 install protobuf
- checkout opus2tonie & patch header
git clone https://github.com/bailli/opus2tonie.git
cd opus2tonie
curl -LOs "https://github.com/bailli/opus2tonie/files/12489794/tonie_header_pb2.py.txt" && mv tonie_header_pb2.py.txt tonie_header_pb2.py
Now you can use opus2tonie.py on the command-line and it should successfully convert any audio file to taf. Until this point, this should work both on macOS and Linux:
python3 opus2tonie.py [INPUT_FILE.mp3] [OUTPUT_FILE.taf]
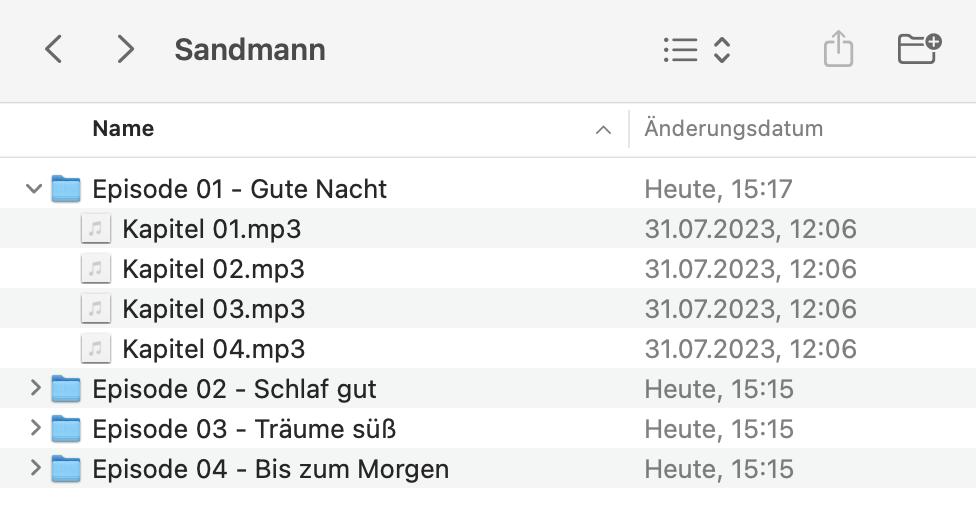
The input can also be a directory. In this case, all files inside the directory will be merged into one single taf file:
python3 opus2tonie.py [INPUT_DIR] [OUTPUT_FILE.taf]
ㅤ
![]() Automator Quick Action (macOS-only)
Automator Quick Action (macOS-only) ![]()
In order to trigger the encoding and Teddycloud upload with a simple right click on your mouse in Finder, we have to set up a new Automator quick action which triggers a shell script.
- open the Automator app
- select “new document” → Quick action
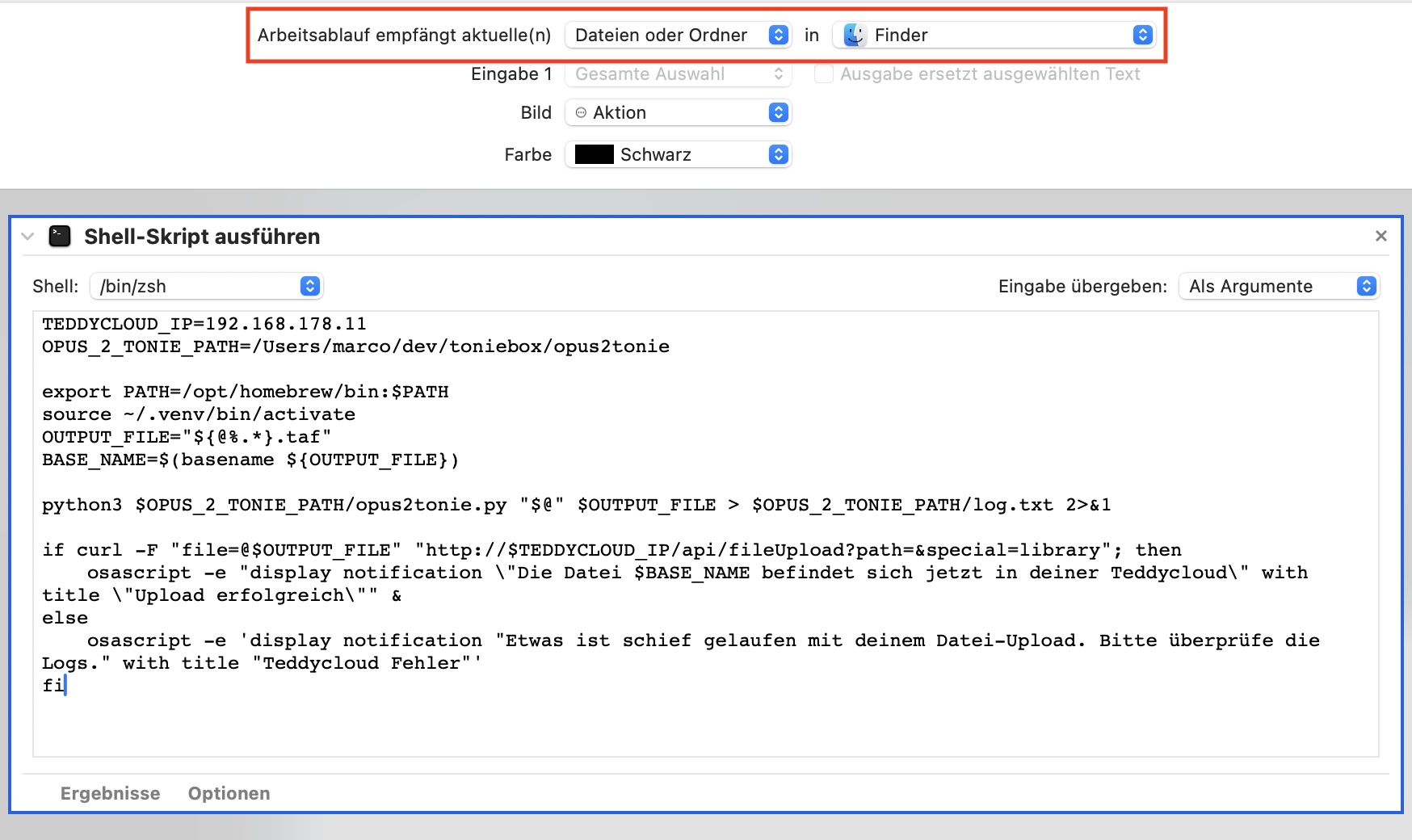
- at the top set “Workflow accepts Files and Folders in Finder”
- type “shell” in the search field and select the “run shell script” action
- paste the following content, change ip address & opus2tonie-path (line 1 & 2)
- save the Quck Action → Name will be the name in your context menu
TEDDYCLOUD_IP=192.168.178.11
OPUS_2_TONIE_PATH=/Users/marco/dev/toniebox/opus2tonie
export PATH=/opt/homebrew/bin:$PATH
source ~/.venv/bin/activate
OUTPUT_FILE="${@%.*}.taf"
BASE_NAME=$(basename ${OUTPUT_FILE})
python3 $OPUS_2_TONIE_PATH/opus2tonie.py "$@" $OUTPUT_FILE > $OPUS_2_TONIE_PATH/log.txt 2>&1
if curl -F "file=@$OUTPUT_FILE" "http://$TEDDYCLOUD_IP/api/fileUpload?path=&special=library"; then
osascript -e "display notification \"Die Datei $BASE_NAME befindet sich jetzt in deiner Teddycloud\" with title \"Upload erfolgreich\"" &
else
osascript -e 'display notification "Etwas ist schief gelaufen mit deinem Datei-Upload. Bitte überprüfe die Logs." with title "Teddycloud Fehler"'
fi
In Automator it should look like this:
Happy transcoding!